本文从源码分析GCD中的DispatchGroup是怎么调度的,notify的背后是如何实现的。如果你对Swift中GCD如何使用不太了解。可以参考《详解Swift多线程》
API
以下代码是DispatchGroup的常用使用场景
let g1 = DispatchGroup.init()
g1.notify(queue: DispatchQueue.global()) {
print("notify null")
}
g1.enter()
DispatchQueue.global().async {
for _ in 0...3{
print("task A: \(Thread.current)")
}
g1.leave()
}
g1.enter()
DispatchQueue.global().async {
for _ in 0...3 {
print("task B: \(Thread.current)")
}
g1.leave()
}
g1.notify(queue: DispatchQueue.global()) {
print("notify A&B")
}
g1.notify(queue: DispatchQueue.global()) {
print("notify A&B again")
}
notify null
task A: <NSThread: 0x600002be85c0>{number = 4, name = (null)}
task B: <NSThread: 0x600002bc5300>{number = 6, name = (null)}
task A: <NSThread: 0x600002be85c0>{number = 4, name = (null)}
task B: <NSThread: 0x600002bc5300>{number = 6, name = (null)}
task A: <NSThread: 0x600002be85c0>{number = 4, name = (null)}
task A: <NSThread: 0x600002be85c0>{number = 4, name = (null)}
task B: <NSThread: 0x600002bc5300>{number = 6, name = (null)}
task B: <NSThread: 0x600002bc5300>{number = 6, name = (null)}
notify A&B
notify A&B again
|
由以上代码结果可以得知,notity之前没有调用enter()和levae()会直接被调用。
如果在notity之前调用了enter()和leave()。notify会在最后一个leave()调用后才会回调。
wait()的使用
let g1 = DispatchGroup.init()
g1.enter()
DispatchQueue.global().async {
for _ in 0...3{
print("task A: \(Thread.current)")
}
g1.leave()
}
g1.enter()
DispatchQueue.global().async {
for _ in 0...3 {
print("task B: \(Thread.current)")
}
sleep(UInt32(3.5))
g1.leave()
}
let result = g1.wait(timeout: .now() + 3)
switch result {
case .success:
g1.notify(queue: DispatchQueue.global()) {
DispatchQueue.global().async {
for _ in 0...3 {
print("task D: \(Thread.current)")
}
}
}
case .timedOut:
print("timedOut")
break
}
//打印结果
timedOut
|
查看源码
Swift使用的GCD是桥接OC的源码。所以底层还是libdispatch。
源码可以去opensource下载:https://opensource.apple.com/tarballs/libdispatch/
也可以去github上Apple官方仓库去下载:https://github.com/apple/swift-corelibs-libdispatch
要注意Apple的源码是一直在迭代升级的。封装也是越来越深,在opensource上可以看到很多版本的源码。写这篇文章时候最新版本为1173.40.5版本。本文分析基于931.60.2版本。网速很多资料的源码都是很老的187.9版本之前。内部实现变动很大。
下载源码后,可以在semaphore.c中找到DispatchGroup的实现。
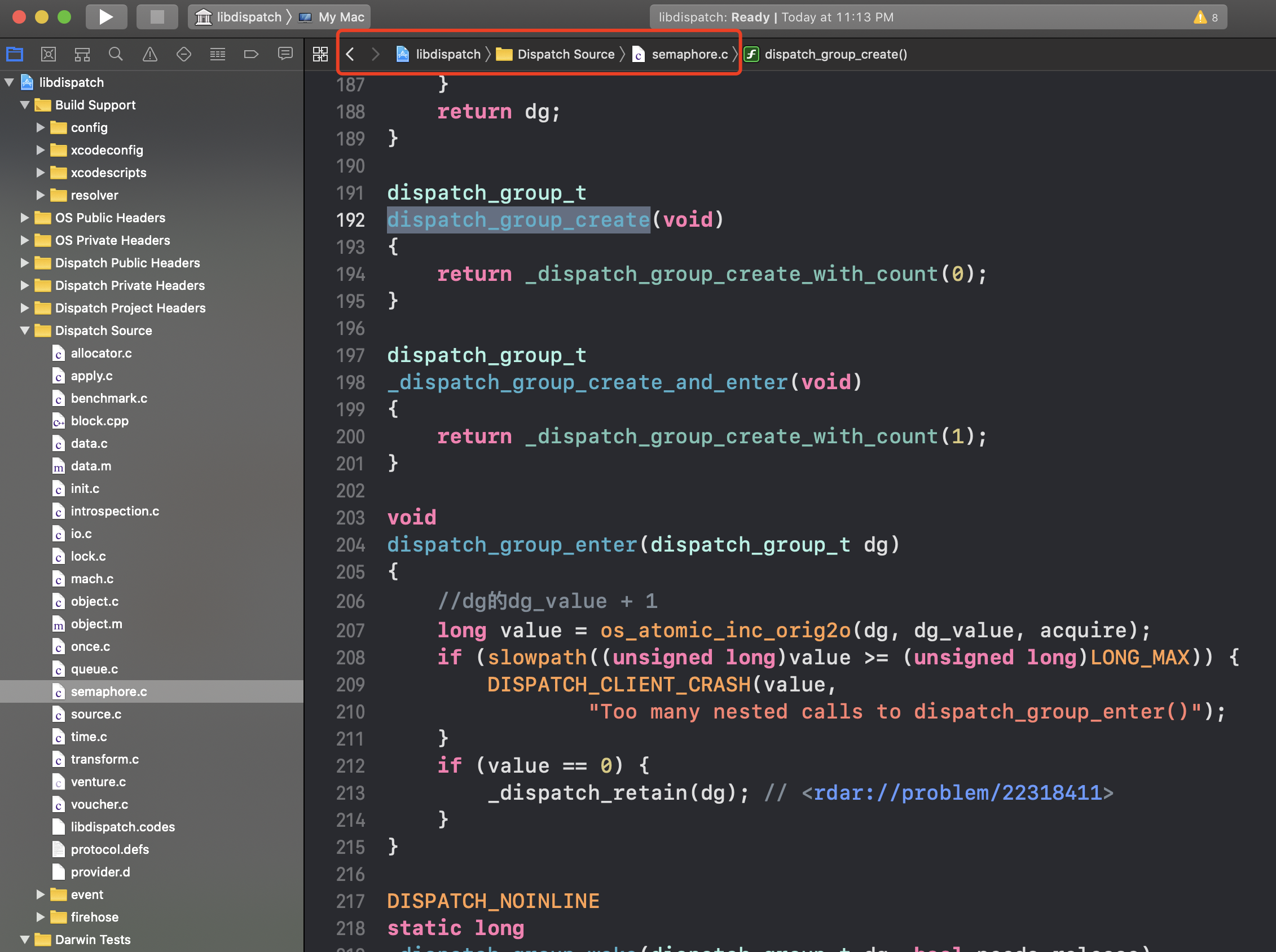
create
先来看看dispatch_group_create的实现
dispatch_group_t
dispatch_group_create(void)
{
return _dispatch_group_create_with_count(0);
}
dispatch_group_t
dispatch_group_create(void)
{
return (dispatch_group_t)dispatch_semaphore_create(LONG_MAX);
}
|
_dispatch_group_create_with_count的实现
DISPATCH_ALWAYS_INLINE
static inline dispatch_group_t
_dispatch_group_create_with_count(long count)
{
dispatch_group_t dg = (dispatch_group_t)_dispatch_object_alloc(
DISPATCH_VTABLE(group), sizeof(struct dispatch_group_s));
_dispatch_semaphore_class_init(count, dg);
if (count) {
os_atomic_store2o(dg, do_ref_cnt, 1, relaxed);
}
return dg;
}
|
我们一个一个来分析
通过搜索发现dispatch_group_t本质上就是dispatch_group_s
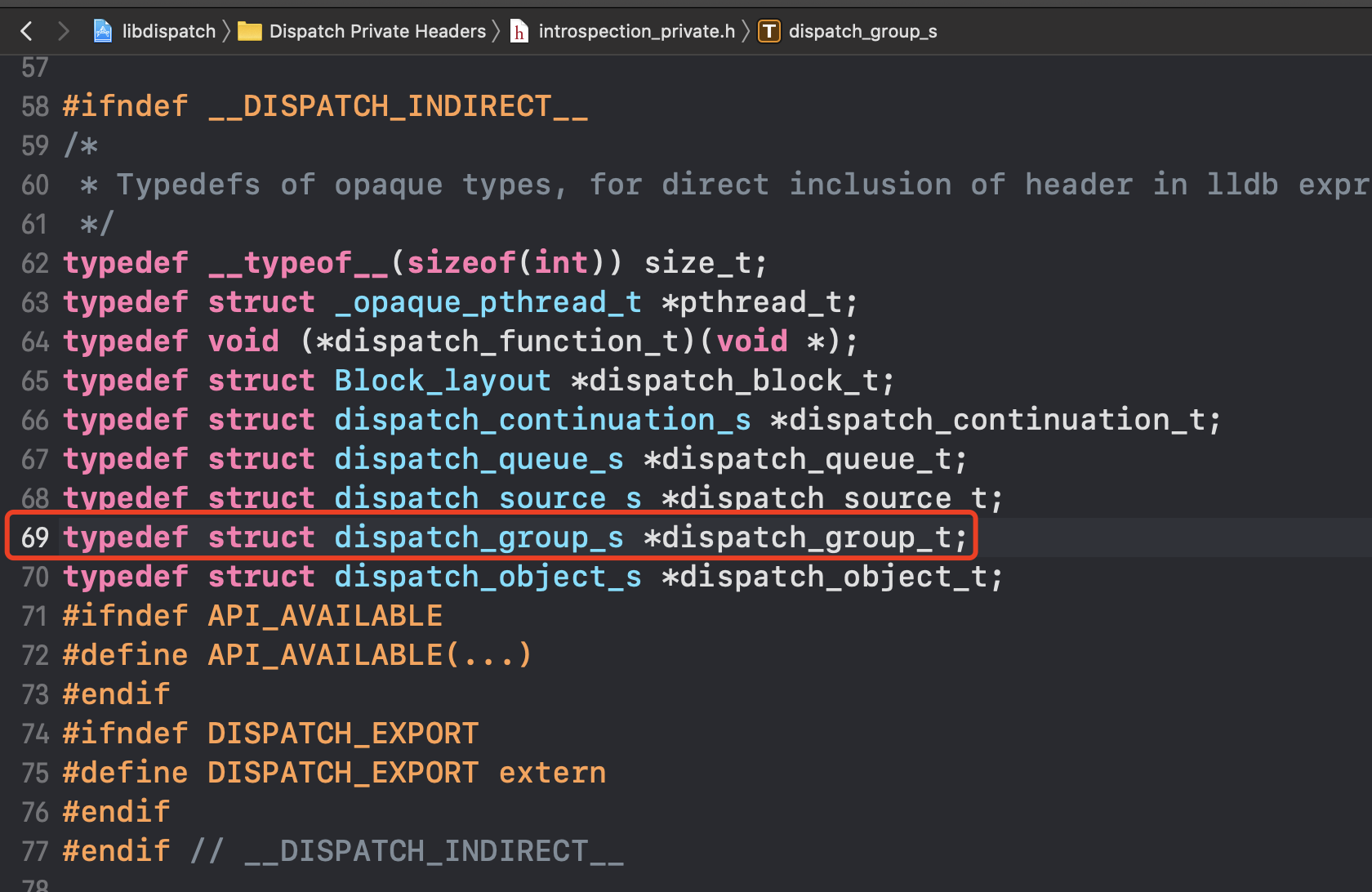
dispatch_group_s是一个结构体
struct dispatch_group_s {
DISPATCH_SEMAPHORE_HEADER(group, dg);
int volatile dg_waiters;
struct dispatch_continuation_s *volatile dg_notify_head;
struct dispatch_continuation_s *volatile dg_notify_tail;
};
|
从上面代码可以看到,creat方法创建了一个dispatch_group_t(也是dispatch_group_s)出来,默认传进来的count是0,并且把count通过dispatch_semaphore_class_init(count, dg)存了起来。
dispatch_semaphore_class_init
static void
_dispatch_semaphore_class_init(long value, dispatch_semaphore_class_t dsemau)
{
struct dispatch_semaphore_header_s *dsema = dsemau._dsema_hdr;
dsema->do_next = DISPATCH_OBJECT_LISTLESS;
dsema->do_targetq = _dispatch_get_root_queue(DISPATCH_QOS_DEFAULT, false);
dsema->dsema_value = value;
_dispatch_sema4_init(&dsema->dsema_sema, _DSEMA4_POLICY_FIFO);
}
|
ok,通过creat方法我们知道我们创建了一个dispatch_group_s出来,并且把0存了起来。知道dispatch_group_s中有一个类似链表的头和尾,看参数名知道和notify有关。
enter()
enter() 本质上调用dispatch_group_enter()
dispatch_group_enter
void
dispatch_group_enter(dispatch_group_t dg)
{
long value = os_atomic_inc_orig2o(dg, dg_value, acquire);
if (slowpath((unsigned long)value >= (unsigned long)LONG_MAX)) {
DISPATCH_CLIENT_CRASH(value,
"Too many nested calls to dispatch_group_enter()");
}
if (value == 0) {
_dispatch_retain(dg);
}
}
|
从源码上看enter没做其余的操作,就是把dg的dg_value做+1操作。如果dg_value值过大就会crash。
leave()
那么同理我们可以想到leave()应该是做-1操作。
void
dispatch_group_leave(dispatch_group_t dg)
{
long value = os_atomic_dec2o(dg, dg_value, release);
if (slowpath(value == 0)) {
return (void)_dispatch_group_wake(dg, true);
}
if (slowpath(value < 0)) {
DISPATCH_CLIENT_CRASH(value,
"Unbalanced call to dispatch_group_leave()");
}
}
|
从源码得知,leave的核心逻辑是判断value==0时候执行_dispatch_group_wake。同时当levae次数比enter多时候,value<0会crash
同时真正执行的逻辑应该在_dispatch_group_wake中
notify()
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_group_notify(dispatch_group_t dg, dispatch_queue_t dq,
dispatch_continuation_t dsn)
{
dsn->dc_data = dq;
dsn->do_next = NULL;
_dispatch_retain(dq);
if (os_mpsc_push_update_tail(dg, dg_notify, dsn, do_next)) {
_dispatch_retain(dg);
os_atomic_store2o(dg, dg_notify_head, dsn, ordered);
if (os_atomic_load2o(dg, dg_value, ordered) == 0) {
_dispatch_group_wake(dg, false);
}
}
}
|
可以看到,核心逻辑还是dg.davalue为0的话,就直接调用_dispatch_group_wake。所以可以解释为什么notify调用之前没有enter和leave为什么会直接被回调。因为没有enter和leave,dg_value为0,直接调用_dispatch_group_wake
_dispatch_group_wake()
可以说DispatchGroup的核心逻辑就在_dispatch_group_wake方法中
先来看看源码实现
DISPATCH_NOINLINE
static long
_dispatch_group_wake(dispatch_group_t dg, bool needs_release)
{
dispatch_continuation_t next, head, tail = NULL;
long rval;
head = os_atomic_xchg2o(dg, dg_notify_head, NULL, relaxed);
if (head) {
tail = os_atomic_xchg2o(dg, dg_notify_tail, NULL, release);
}
rval = (long)os_atomic_xchg2o(dg, dg_waiters, 0, relaxed);
if (rval) {
_dispatch_sema4_create(&dg->dg_sema, _DSEMA4_POLICY_FIFO);
_dispatch_sema4_signal(&dg->dg_sema, rval);
}
uint16_t refs = needs_release ? 1 : 0;
if (head) {
do {
next = os_mpsc_pop_snapshot_head(head, tail, do_next);
dispatch_queue_t dsn_queue = (dispatch_queue_t)head->dc_data;
_dispatch_continuation_async(dsn_queue, head);
_dispatch_release(dsn_queue);
} while ((head = next));
refs++;
}
if (refs) _dispatch_release_n(dg, refs);
return 0;
}
|
是否还记得前面提到的dispatch_group_s中的链表头和尾?
head = os_atomic_xchg2o(dg, dg_notify_head, NULL, relaxed);
|
这里取出dispatch_group_s中的链表头,如果有链表头再取出链表尾。
核心逻辑在这个do while循环中
if (head) {
do {
next = os_mpsc_pop_snapshot_head(head, tail, do_next);
dispatch_queue_t dsn_queue = (dispatch_queue_t)head->dc_data;
_dispatch_continuation_async(dsn_queue, head);
_dispatch_release(dsn_queue);
} while ((head = next));
refs++;
}
|
通过head->dc_data拿到目标队列,然后通过_dispatch_continuation_async(dsn_queue, head)将head运行在目标队列上。
那head是什么就一目了然了。这个队列中存储的是notify回调的block
再来看看dispatch_group_s的定义
struct dispatch_group_s {
DISPATCH_SEMAPHORE_HEADER(group, dg);
int volatile dg_waiters;
struct dispatch_continuation_s *volatile dg_notify_head;
struct dispatch_continuation_s *volatile dg_notify_tail;
};
|
总结
DispatchGroup 在创建时候会建立一个链表,来存储notify的block回调。
判断notify执行的依据就是dg_value是否为0
当不调用enter和leave时候,dg_value=0,notify的回调会立即执行,并且有多个notify会按照顺序依次调用。
let g1 = DispatchGroup.init()
g1.notify(queue: DispatchQueue.global()) {
print("notify null")
}
g1.notify(queue: DispatchQueue.global()) {
print("notify null2")
}
|
当有enter时候dg_value+1。leave时候-1。
当最后一个leave执行后,dg_value==0。去循环链表执行notify的回调
let g1 = DispatchGroup.init()
//A B 并发 A B 完成后开启C任务
g1.enter()
DispatchQueue.global().async {
for _ in 0...3{
print("task A: \(Thread.current)")
}
g1.leave()
}
g1.enter()
DispatchQueue.global().async {
for _ in 0...3{
print("task B: \(Thread.current)")
}
g1.leave()
}
g1.notify(queue: DispatchQueue.global()) {
print("notify A&B")
}
}
|
根据源码也得知,enter和leave必须成对出现。
当enter多的时候,dg_value永远大于0,notify不会被执行。
当leave多的时候,dg_value小于0,造成Crash
思考
Apple的API封装的很好,其中的一些设计模式也值得我们学习。
GCD的执行效率特别高,在读源码中发现if判断用了很多slowpath fastpath
void
dispatch_group_leave(dispatch_group_t dg)
{
long value = os_atomic_dec2o(dg, dg_value, release);
if (slowpath(value == 0)) {
return (void)_dispatch_group_wake(dg, true);
}
if (slowpath(value < 0)) {
DISPATCH_CLIENT_CRASH(value,
"Unbalanced call to dispatch_group_leave()");
}
}
|
这个会再另起一篇博客来研究。
关于DispatchGroup 的wait()实现就不再分析了。大家可以自行下载源码来研究下。
带注释的源码详见Github:
https://github.com/liweican1992/libdispatch
https://github.com/liweican1992/swift-corelibs-foundation